
Andrej Karpathy released a series of timeless lectures teaching us mortal 9-5 programmers from scratch how to train an “AI” language model, a bit like that GPT4 or ChatGPT you may have heard of.
He goes into a deep dive that includes building your own tiny Pytorch from scratch, setting up bigram models, and simple neural nets, before moving over to use the real Pytorch later. He then explains how transformers (the T in GPT) work, and codes one up to generate some dubious Shakespeare. This final model he calls “NanoGPT”, because of the similarity between it’s model and that of the early GPT models that lead to ChatGPT.
So why this post?
Well, while I absolutely loved the series, I don’t enjoy working with Colab or Jupyter Notebooks. It is easy to forget what code blocks have run, and I am forever scrolling up and down because the code is mixed up with results in one giant page. Not only that but if you are using Google Colab it will time out fairly quicky so you need to waste time running everything again.
⚠️Warning: I don’t think I recommend doing what I do here anymore. It works but is super fiddly. I am working on a much easier way to do this with a single Python file you download and run. So please read bearing that in mind…
I’d run it on my machine instead, but…
I want to run NanoGPT locally but I don’t have a good GPU. To save buying one for $2000+, I would like to rent one in the cloud if possible. If I use cloud GPUs I can experiment quickly with different chips as needed. An A100 GPU for example costs maybe $7000 – $15000 USD, but grabbing one for an hour for $4 is much more in my budget.
modal.com provides this service, and they take care of all of the “devops” as we will see soon. There is some housekeeping Python code to write, but no bash, Terraform or Ansible, which is great because I don’t want to do that.
Their GPU prices are not the cheapest. I would say they charge fair (average) prices though. And they charge for the milliseconds of actual usage and nothing else. That means I don’t pay extra because I forgot to shut down a server. Also they include $40/month credit for free anyway so it is costing me nothing to learn.
In this post I will show you how I used Modal to quickly train and run the NanoGPT model, while having the creature comforts of developing in VSCode.
What is NanoGPT anyway?
NanoGPT is nothing but a text producing bot!
When trained on some text it will learn how to predict the next character. So for example if you feed it “Hello ” it might predict W. You then feed it “Hello W” and it might predict o and so on. By repeating this you get text generation.
When trained on Shakespeare it makes muddled text that is quite a bit Shakespeare-looking.
Example of NanoGPT generated text:
FlY BOLINGLO: Them thrumply towiter arts the muscue rike begatt the sea it What satell in rowers that some than othis Marrity.
LUCENTVO: But userman these that, where can is not diesty rege; What and see to not. But’s eyes. What?
JOHN MARGARET: Than up I wark, what out, I ever of and love, one these do sponce, vois I me; But my pray sape to ries all to the not erralied in may.
If you want to know more, you can check out:
- Video (with links to resources)
- Google Colab code
- Github code
Now let’s get started, and get NanoGPT trained and running with local code, and a cloud GPU from Modal.
Step 1: Learn how to run code on Modal
I won’t parrot too much what Modal have in their tutorials, as that is the best place to go, but in a nutshell you can decorate functions in Python that you want to run on their servers.
For example you have a function you want to run in their cloud:
@stub.function()
def f(i):
if i % 2 == 0:
print("hello", i)
else:
print("world", i, file=sys.stderr)
return i * iAnd then you can call this from a local function either as-is (to run locally) or with .call (to run on the server):
@stub.local_entrypoint()
def main():
# Call the function locally.
print(f(1000))
# Call the function remotely.
print(f.call(1000))To run this from the command line:
modal deploy example.pyStep 2: Fork the NanoGPT repo, and check it works on local computer
The next step is to make a fork of https://github.com/karpathy/nanoGPT and clone that fork to my computer, so that I can make some changes to adapt it to use Modal.
Note: If using Windows, you will need to use a Linux distribution installed to WSL2 to do this successfully as Windows is not supported for torch.compile
It is a good idea to check that we can get it to run locally. I just want to check the code works fast so I will reduce the number of iterations in train_shakespeare_char.py to 5, and dumb down the model size to ridiculously small so it completes in a few seconds on a crap laptop. Here are the changed lines in train_shakespeare_char.py:
...
max_iters = 5
...
# baby GPT model :)
n_layer = 2
n_head = 4
n_embd = 16
dropout = 0.2
...In addition, I uncomment these 2 lines in the same file (train_shakespeare_char.py) to make it possible to run on an average laptop with no GPU:
# on macbook also add
device = 'cpu' # run on cpu only
compile = False # do not torch compile the modelTo check that it works, I set up a Python environment, and run similar commands as shown in the NanoGPT README.md:
python -m venv .
source bin/activate
pip install torch numpy transformers datasets tiktoken wandb tqdm
python data/shakespeare_char/prepare.py
python train.py config/train_shakespeare_char.pyFrom this we get a confirmation that this training loop is running correctly:
step 0: train loss 4.1783, val loss 4.1771
iter 0: loss 4.1791, time 47896.67ms, mfu -100.00%Knowing that it works on my computer makes me more confident to try and getting it working on Modal.
Step 3: Upload the training data to modal
3.1 Authenticate with modal
First, lets do the basic setup for Modal and get authenticated:
pip install modal-client
modal token new3.2 Change the prepare.py to upload to Modal
Now edit data/shakespeare_char/prepare.py, and nest the existing code inside a main function. Add a @stub.local_entrypoint() decorator, so that Modal knows to run this locally.
@stub.local_entrypoint()
def main():
"""
Prepare the Shakespeare dataset for character-level language modeling.
So instead of encoding with GPT-2 BPoE tokens, we just map characters to ints.
Will save train.bin, val.bin containing the ids, and meta.pkl containing the
encoder and decoder and some other related info.
"""
import os
import pickle
...Add the following lines at the top of the file to define the volume and app name:
import modal
volume = modal.NetworkFileSystem.new().persisted("nano-gpt-volume")
stub = modal.Stub("nano-gpt-code")Now add this function at the bottom, which will run on the remote server. All it does is copies the files over with some prints to check if it was successful. It keeps the folder structure on the server the same (the working directory is /root there) so that there is less code to change in train.py when we get to it.
dataset = "shakespeare_char"
@stub.function(
mounts=[modal.Mount.from_local_dir("data", remote_path="/source/data")],
network_file_systems={"/root/data": volume})
def copy():
import shutil
import os
source_dataset_path = os.path.join("/source/data", dataset)
dest_dataset_path = os.path.join("/root/data", dataset)
def check():
if os.path.exists(dest_dataset_path):
files = os.listdir(dest_dataset_path)
print(f"Files: {str.join(', ', files)}")
else:
print(f"Path doesn't exist")
check()
shutil.copytree(source_dataset_path, dest_dataset_path, dirs_exist_ok=True)
print("files copied")
check()
Now make the call to copy from main:
...
# val has 111540 tokens
copy.call()3.3 Run the upload
You can now run this to perform the upload:
modal run data/shakespeare_char/prepare.pyYou should get an output like this:
Path doesn't exist
files copied
Files: meta.pkl, val.bin, prepare.py, input.txt, __pycache__, train.bin, readme.mdIf you run it again, it should show that the files exist before it is copied, proving that the data was persisted. Now the remote machine has access to the training data.
Step 4: Adapt the training code to run on Modal
4.1 Make the training code into a Python package
As far as I can tell, in order for Modal to see all of your Python code it must be organised in a package.
To make the code into a Python package those is quite simple, first move the python files for the model training and text generation into a new folder:
mkdir nanogpt
mv config *.py nanogptFind all instances of from model in these files, and replace with from .model (Add a period). For example in train.py:
from .model import GPTConfig, GPTAdding a period to these local imports says “this is from the current directory’s package”. This allows the code to work when called from another package or location, which will be doing when using Modal.
4.2 Remove the configurator
There is a line in train.py that needs to be commented out because it won’t work in Modal (because it doesn’t have the source files in the same place), so comment this out, and add a hard-coded line that does the equivalent thing for the Shakespeare model.
# exec(open('nanogpt/configurator.py').read()) # overrides from command line or config file
from .config.train_shakespeare_char import *This is perhaps not the ideal way to do it, but a quick change for the purposes of making this blog post not too long.
4.3 Add a python script to run the code in Modal
Create a new file called train.modal.py in the root of the project (so one up from nanogpt folder) and add the code below. I have put some comments in there to explain it.
import modal
# Make sure we have access to the data we prepared earlier:
volume = modal.NetworkFileSystem.new().persisted("nano-gpt-volume")
# Set up the container for running the training, and make sure it has the necessary
# python pacakages installed.
stub = modal.Stub("nano-gpt-train",
image=modal.Image.debian_slim().pip_install(
["torch", "numpy", "transformers", "datasets", "tiktoken", "wandb", "tqdm"]
)
)
# This stub.function allows train_modal to be called remotely on their servers. We will
# now specify how we want that set up...
@stub.function(
# Ensure that the function runs with a GPU, I have picked out a cheap one, but you can replace
# this with "any" in the future if this GPU is no longer available.
gpu=modal.gpu.T4(),
# Increase the timeout to allow long training times.
timeout=3600,
# This tells modal to upload the entire nanogpt package we created. Without doing
# this it won't be able to locate train.py, model.py etc.
mounts=[modal.Mount.from_local_python_packages("nanogpt")],
# Mount the data we prepared earlier
network_file_systems={"/root/data": volume}
)
def train_modal():
# This import is a cheeky and quick way to run nanogpt with minimal changes to Andrej's code. Ideally we would change
# the `train`` module to expose a function. Then import `train` and call that function.ction and call that.
import nanogpt.train
# This is what gets called locally when running `modal run train_modal.py`, and it just calls the
# remote function.
@stub.local_entrypoint()
def main():
train_modal.call()
With a GPU available, we can comment these 2 lines back out in train_shakespeare_char.py:
# on macbook also add
# device = 'cpu' # run on cpu only
# compile = False # do not torch compile the modelWe also want the checkpoint saving to work (which saves the progress so we can resume on error, and also to run the model later). Because we mounted a folder called data, make the following change, otherwise the checkpoints wont be saved:
out_dir = 'data/out-shakespeare-char'4.4 Run the script
Now we can run this from the command line: modal run train_modal.py, and here is the result:
(nanoGPTonModal) martin@Capo:~/nanoGPTonModal$ modal run train_modal.py
✓ Initialized. View app at https://modal.com/apps/ap-k9Oehw5IpXCxmt3yNBUNds
✓ Created objects.
├── 🔨 Created train_modal.
├── 🔨 Created mount /home/martin/nanoGPTonModal/nanogpt
└── 🔨 Created mount /home/martin/nanoGPTonModal/train_modal.py
tokens per iteration will be: 16,384
found vocab_size = 65 (inside data/shakespeare_char/meta.pkl)
Initializing a new model from scratch
number of parameters: 0.01M
num decayed parameter tensors: 10, with 11,280 parameters
num non-decayed parameter tensors: 5, with 80 parameters
using fused AdamW: True
step 0: train loss 4.1783, val loss 4.1771
iter 0: loss 4.1791, time 3620.00ms, mfu -100.00%
✓ App completed.4.5. Revert to the proper sized hyper-parameters
Revert the values in train_shakespeare_char.py to the bigger model values, with more iterations. Now we are using Modal, this will be able to run in a reasonable time.
...
max_iters = 5000
...
# baby GPT model :)
n_layer = 6
n_head = 6
n_embd = 384
dropout = 0.2
...Tip, the next step takes about 15 minutes. If it makes training progress (says checkpoint has been created) but then gets stopped, you can resume it by setting init_from = 'resume' in the parameters above.
Running modal run train_modal.py again:
\(nanoGPTonModal) martin@Capo:~/nanoGPTonModal$modal run train_modal.py
✓ Initialized. View app at https://modal.com/apps/ap-HU6D2SRnxOv1OsJpmlb3Fj
✓ Created objects.
├── 🔨 Created train_modal.
├── 🔨 Created mount /home/martin/nanoGPTonModal/nanogpt
└── 🔨 Created mount /home/martin/nanoGPTonModal/train_modal.py
tokens per iteration will be: 16,384
found vocab_size = 65 (inside data/shakespeare_char/meta.pkl)
Initializing a new model from scratch
number of parameters: 10.65M
num decayed parameter tensors: 26, with 10,740,096 parameters
num non-decayed parameter tensors: 13, with 4,992 parameters
using fused AdamW: True
compiling the model... (takes a ~minute)
step 0: train loss 4.2874, val loss 4.2823
iter 0: loss 4.2649, time 29573.95ms, mfu -100.00%
iter 10: loss 3.2438, time 101.76ms, mfu 3.66%
iter 20: loss 2.7899, time 103.62ms, mfu 3.66%
iter 30: loss 2.6383, time 104.10ms, mfu 3.65%
iter 40: loss 2.5763, time 101.83ms, mfu 3.65%
iter 50: loss 2.5261, time 104.54ms, mfu 3.64%
iter 60: loss 2.5136, time 103.90ms, mfu 3.64%
...
iter 4980: loss 1.2050, time 117.62ms, mfu 3.16%
iter 4990: loss 1.2493, time 114.90ms, mfu 3.17%
step 5000: train loss 1.1405, val loss 1.4969
iter 5000: loss 1.2446, time 12044.48ms, mfu 2.86%
✓ App completed.Costs
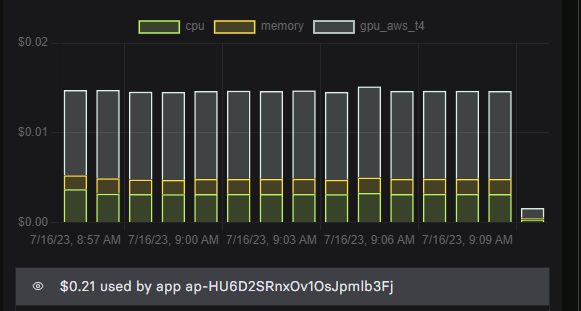
It took about 14 minutes and cost $0.21 to train the model. I think $0.14 was for the GPU and the rest was for CPU/memory.
Conclusion
First, this took a little more work than expected to get some local python code running on Modal.
The combination of design choices in the nanoGPT repo, and the fairly narrow happy path to get code to run in Modal meant that a lot of changes had to be made. To summarize these things meant code changes were needed:
- Modal will only upload a bunch of Python files if specified as a package. NanoGPT didn’t do this.
- Modal will put the files “somewhere”, so using exec() on relative paths to local scripts like NanoGPT does won’t work.
- Modal requires additional functions and decorations, so a new file is needed.
- Modal requires specification of mounts etc. so this new file has quite a bit to it.
I think if you build a Python project with Modal in mind, then the experience will be easier. You will know how to organize files, what not to do, etc. So there will be less work to do.
Next, it is worth saying that once you get this working, it works really well. Running modal run train_modal.py it gets going and chugs along, you almost forget this is doing a whole bunch of ops stuff in the cloud for you. Then you can iterate and change things up and Modal gets out of your way a bit.
With Modal set up, I can now code with an IDE, IDE Plugins, file structure, git, etc. It is more what I am used to than the Jupyter experience where you have to remember what state things are in, there is effectively one big file, and output and code are all mixed up. This is much better.
Therefore overall I think Modal is worth learning and experimenting with, and putting that initial effort to get set up. Or if money is no object, just go buy a big GPU :-).
Next
In the next blog post I run the text generation to see what kind of Shakespeare this model can produce. This will require some code changes to get that to work on Modal, but I expect it to be a lot less as much of the work has been done.
I will also explore what other features are in NanoGPT and try them out using Modal too.